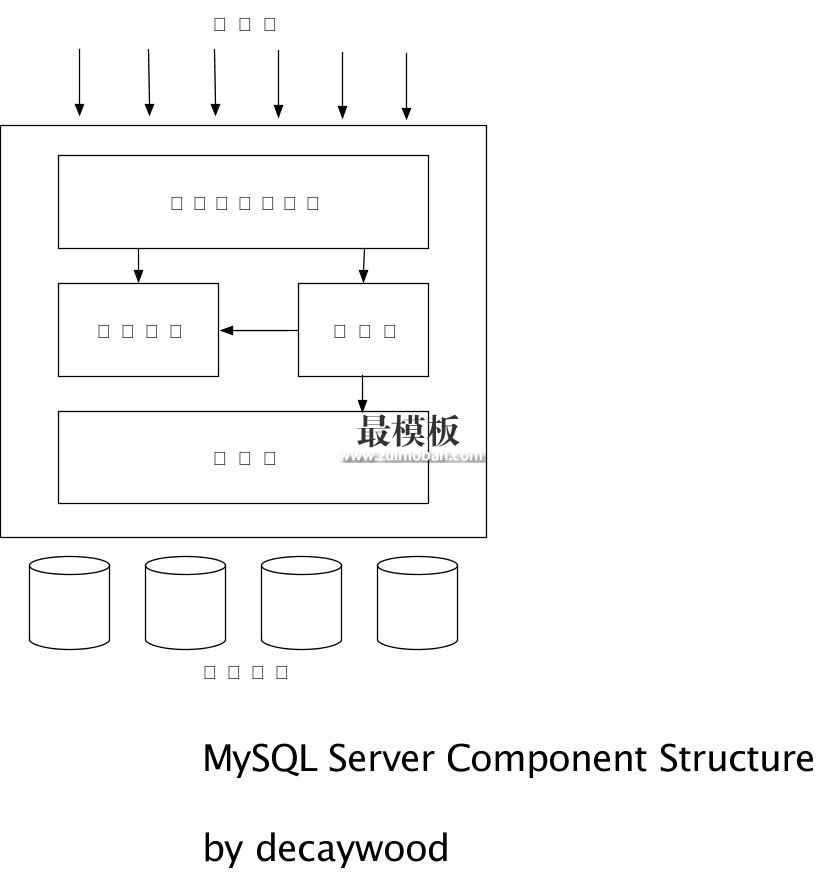
MySQL的逻辑体系结构
最上层的服务并不是MySQL所独有的,大多数基于网络的客户端/服务器的工具都有类似的架构。比如连接处理、授权认证、安全等等。 第二层架构是MySQL比较有意思的部分。大多数MySQL的核心服务功能都在这一层,包括查询解析、分析、优化、缓存以及所有内置函数(例如:日期、时间、数学和加密函数),所有跨存储引擎的功能都在这一层实现:存储过程,触发器,视图等。 第三层包含了存储引擎。存储引擎负责MySQL中数据的存储和提取。和GNU/Linux下的各种文件系统一样,每个存储引擎都有它的优势和劣势。服务器通过API与存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明。存储引擎API包含十几个底层函数,用于执行诸如“开始一个事物”或者“根据主键提取一行记录”等操作。但存储引擎不会去解析SQL(注:InnoDB是一个例外,它会解析外键定义,因为MySQL服务器本身没有实现该功能),不同存储引擎之间也不会互相通信,而只是简单地响应上层服务器的请求。 连接管理与安全每个客户端连接都会在服务器进程中拥有一个线程,这个连接的查询只会在这个单独的线程中执行,该线程只能轮流在某个CPU核心或者CPU中运行。服务器会负责缓存线程,因此不需要为每一个新建的连接创建或者销毁线程。(注:MySQL5.5或者更新的版本提供的一个API,支持线程池插件,可以使用池中少量的线程来服务大量的连接)。 当客户端(应用)连接到MySQL服务器时,服务器需要对其进行认证。认证基于用户名,原始主机信息和密码。如果使用了安全套接字(SSL)的方式连接,还可以使用X.509证书认证。一旦客户端连接成功,服务器会继续验证客户端是否具有某个特定查询的权限(例如,是否允许客户端对world数据库的Country表执行SELECT语句)。 优化与执行MySQL会解析查询,并创建内部数据结构(解析树),然后对其进行各种优化,包括重写查询,决定表的读取顺序,以及选择合适的索引等。用户可以通过特殊的关键字提示(hint)优化器,影响它的决策过程。也可以请求优化器解释(explain)优化过程的各个因素,使用户可以知道服务器是如何进行优化决策的,并提供一个参考基准,便于用户重构查询和schema,修改相关配置,是应用尽可能高效运行。 优化器并不关心使用的是什么存储引擎,但存储引擎对于优化查询是有影响的。优化器会请求存储引擎提供容量或某个具体操作的开销信息,以及表数据的统计信息等。例如,某些存储引擎的某种索引,可能对一些特定的查询有优化。 对于SELECT语句,在解析查询之前,服务器会先检查查询缓存(Query Cache),如果能够在其中找到对应的查询,服务器就不必再执行查询解析、优化和执行的整个过程,而是直接返回查询缓存中的结果集。 查询的过程以及开销查询的过程:从客户端到服务端,在服务器上进行解析,生成执行计划,执行,并返回结果给客户端,执行包括了大量为了检索数据到存储引擎的调用以及调用后的数据处理,包括排序,分组。 查询的开销:MySQL的解析,优化,锁等待,以及数据处理等,存储引用的API的调用。 SQL标准的执行流程(select)
(8) SELECT
(9) DISTINCT
(11) <TOP_specification> <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) WITH {CUBE ROLLUP}
(7) HAVING <having_condition>
(10) ORDER BY <order_by_list>
SQL 中的 JOIN
nested loop join 算法(对连接的优化)在MySQL中,只有一种 Join 算法,就是大名鼎鼎的 Nested Loop Join,他没有其他很多数据库所提供的 Hash Join,也没有 Sort Merge Join。顾名思义,Nested Loop Join 实际上就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果还有第三个参与 Join,则再通过前两个表的 Join 结果集作为循环基础数据,再一次通过循环查询条件到第三个表中查询数据,如此往复。 MySQL用一次扫描多次连接(single-sweep,multi-join)的方法来解决连接。这意味着MySQL从第一个表中读取一条记录,然后在第二个表中查找到对应的记录,然后在第三个表 中查找,依次类推。当所有的表都扫描完了,它输出选择的字段并且回溯所有的表,直到找不到为止,因为有的表中可能有多条匹配的记录下一条记录将从该表读取,再从下一个表开始继续处理。 MySQL 执行计划的理解id:本次 select 的标识符。在查询中每个 select 都有一个顺序的数值。 select_type:
table:记录查询引用的表。 type:以下列出了各种不同类型的表连接,依次是从最好的到最差的: SYSTEM > CONST > EQ_REF > REF > RANGE > INDEX > ALL(不仅仅是连接,单表查询也会有)
possible_keys:possible_keys字段是指 MySQL 在搜索表记录时可能使用哪个索引。注意,这个字段完全独立于 explain 显示的表顺序。这就意味着 possible_keys 里面所包含的索引可能在实际的使用中没用到。如果这个字段的值是null,就表示没有索引被用到。这种情况下,就可以检查 where子句中哪些字段那些字段适合增加索引以提高查询的性能。就这样,创建一下索引,然后再用 explain 检查一下。想看表都有什么索引,可以通过 show index from tbl_name 来看。 key:key字段显示了 MySQL 实际上要用的索引。当没有任何索引被用到的时候,这个字段的值就是null。想要让 MySQL 强行使用或者忽略在 possible_keys 字段中的索引列表,可以在查询语句中使用关键字 force index、 use index 或 ignore index。 key_len:key_len 字段显示了MySQL使用索引的长度。当 key 字段的值为 null时,索引的长度就是 null。注意,key_len的值可以告诉你在联合索引中 MySQL 会真正使用了哪些索引。 ref:ref 字段显示了哪些字段或者常量被用来和 key 配合从表中查询记录出来。 rows:rows 字段显示了 MySQL 认为在查询中应该检索的记录数。MySQL 认为的得到结果需要读取的记录数,不是返回的记录数。 extra:
|
如何理解MySQL的执行计划
时间:2017-04-09 13:58来源:未知 作者:最模板 点击:次
MySQL的逻辑体系结构 最上层的服务并不是MySQL所独有的,大多数基于网络的客户端/服务器的工具都有类似的架构。比如连接处理、授权认证、安全等等。 第二层架构是MySQL比较有意思的

顶一下
(0)
0%
踩一下
(0)
0%
------分隔线----------------------------
- 上一篇:MySQL查看、创建和删除索引的方法
- 下一篇:没有了
- 热点内容
-
- MySQL 删除binlog日志文件
查看当前日志文件列表: show binary logs; 设置日志保留时长expir...
- MySQL 5.7 新的权限与安全问题
SQL Error (1130): Host 192.168.1.100 is not allowed to connect to this MySQL serv...
- 互联网公司为啥不使用mysql分区表?
缘起:有个朋友问我分区表在58的应用,我回答不出来,在我印...
- MYSQL的随机查询的实现方法 - smart
MYSQL的随机抽取实现方法。举个例子,要从tablename表中随机提取...
- MySQL提示“too many connections”的解决
登陆到MySQL的提示符下,数据show processlist这个命令,可以得到所...
- MySQL 删除binlog日志文件
- 随机模板
-
-
 ecshop仿绿森电器数码商城
人气:500
ecshop仿绿森电器数码商城
人气:500
-
 shopex家天下模板
人气:1661
shopex家天下模板
人气:1661
-
 ecshop仿1号店2014豪华至尊模
人气:1165
ecshop仿1号店2014豪华至尊模
人气:1165
-
 ecshop银联插件接口
人气:3457
ecshop银联插件接口
人气:3457
-
 ecshop精仿橡果国际2011整站
人气:1529
ecshop精仿橡果国际2011整站
人气:1529
-
 ecshop新京东商城高精仿制
人气:2428
ecshop新京东商城高精仿制
人气:2428
-