MySQL排序其实是一个老生常谈的问题了,但是我们这次想由浅入深详细说说MySQL排序模式,怎么影响MySQL选择不同的排序模式和怎么优化排序。 同时也希望通过这篇文章解决大家的以下疑问:
二、排序,排序,排序我们通过explain查看MySQL执行计划时,经常会看到在Extra列中显示Using filesort。 其实这种情况就说明MySQL使用了排序。 Using filesort经常出现在order by、group by、distinct、join等情况下。 三、索引优化排序看到排序,我们的DBA首先想到的肯定是,是否可以利用索引来优化。 InnoDB默认采用的是B tree索引,B tree索引本身就是有序的,如果有一个查询如下: select * from film where actor_name='苍老师' order by prod_time; 那么只需要加一个( actor_name,prod_time )的索引就能够利用B tree的特性来避免额外排序。 如下图所示:
通过B-tree查找到actor_name=’苍老师’演员为苍老师的数据以后,只需要按序往右查找就可以了,不需要额外排序操作。 对应的哪些可以利用索引优化排序的列举如下: SELECT * FROM t1 ORDER BY key_part1,key_part2,... ; SELECT * FROM t1 WHERE key_part1 = constant ORDER BY key_part2; SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 DESC; SELECT * FROM t1 WHERE key_part1 = 1 ORDER BY key_part1 DESC, key_part2 DESC; SELECT * FROM t1 WHERE key_part1 > constant ORDER BY key_part1 ASC; SELECT * FROM t1 WHERE key_part1 < constant ORDER BY key_part1 DESC; SELECT * FROM t1 WHERE key_part1 = constant1 AND key_part2 > constant2 ORDER BY key_part2; 从以上例子里面我们也可以看到,如果要让MySQL使用索引优化排序应该怎么建组合索引。 四、排序模式4.1 实际trace结果但是还是有非常多的SQL没法使用索引进行排序,例如 select * from film where Producer like '东京热%' and prod_time>'2015-12-01' order by actor_age; 我们想查询“东京热”出品的,从去年12月1号以来,并且按照演员的年龄排序的电影信息。 (好吧,假设我这里有一个每一位男DBA都想维护的数据库:) 这种情况下,使用索引已经无法避免排序了,那MySQL排序到底会怎么做列。 笼统的来说,它会按照:
空口无凭,我们可以利用MySQL的optimize trace来查看是否如上所述。 如果通过optimize trace看到更详细的MySQL优化器trace信息,可以查看阿里印风的博客初识5.6的optimizer trace。 trace结果如下:
"join_execution": {
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`film`",
"field": "actor_age"
}
],
"filesort_priority_queue_optimization": {
"usable": false,
"cause": "not applicable (no LIMIT)"
},
"filesort_execution": [
],
"filesort_summary": {
"rows": 1,
"examined_rows": 5,
"number_of_tmp_files": 0,
"sort_buffer_size": 261872,
"sort_mode": "<sort_key, packed_additional_fields>"
}
}
]
}
这里,我们可以明显看到,MySQL在执行这个select的时候执行了针对film表 .actor_age 字段的asc排序操作。
"filesort_information": [
{
"direction": "asc",
"table": "`film`",
"field": "actor_age"
}
4.2 排序模式概览我们这里主要关心MySQL到底是怎么排序的,采用了什么排序算法。 请关注这里 "sort_mode": "<sort_key, packed_additional_fields>" MySQL的sort_mode有三种。 摘录5.7.13中sql/filesort.cc源码如下:
Opt_trace_object(trace, "filesort_summary")
.add("rows", num_rows)
.add("examined_rows", param.examined_rows)
.add("number_of_tmp_files", num_chunks)
.add("sort_buffer_size", table_sort.sort_buffer_size())
.add_alnum("sort_mode",
param.using_packed_addons() ?
"<sort_key, packed_additional_fields>" :
param.using_addon_fields() ?
"<sort_key, additional_fields>" : "<sort_key, rowid>");
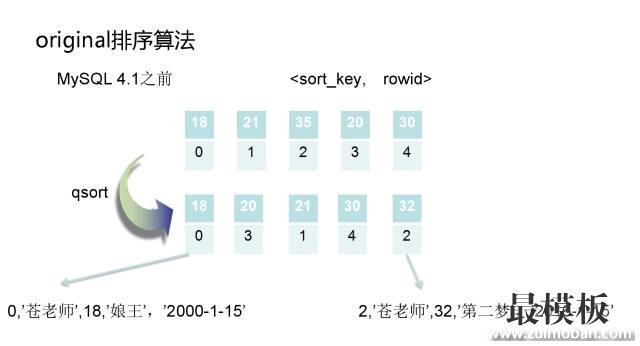
< sort_key, rowid >”和“< sort_key, additional_fields > 看过其他介绍介绍MySQL排序文章的同学应该比较清楚, < sort_key, packed_additional_fields > 相对较新。
下面我们来一一介绍这三个模式: 4.2.1 回表排序模式
4.2.2 不回表排序模式
4.2.3 打包数据排序模式第三种排序模式的改进仅仅在于将char和varchar字段存到sort buffer中时,更加紧缩。 在之前的两种模式中,存储了“yes”3个字符的定义为VARCHAR(255)的列会在内存中申请255个字符内存空间,但是5.7.3改进后,只需要存储2个字节的字段长度和3个字符内存空间(用于保存”yes”这三个字符)就够了,内存空间整整压缩了50多倍,可以让更多的键值对保存在sort buffer中。 4.2.4 三种模式比较第二种模式是第一种模式的改进,避免了二次回表,采用的是用空间换时间的方法。 但是由于sort buffer就那么大,如果用户要查询的数据非常大的话,很多时间浪费在多次磁盘外部排序,导致更多的IO操作,效率可能还不如第一种方式。 所以,MySQL给用户提供了一个 max_length_for_sort_data 的参数。当“排序的键值对大小” > max_length_for_sort_data 时,MySQL认为磁盘外部排序的IO效率不如回表的效率,会选择第一种排序模式;反之,会选择第二种不回表的模式。
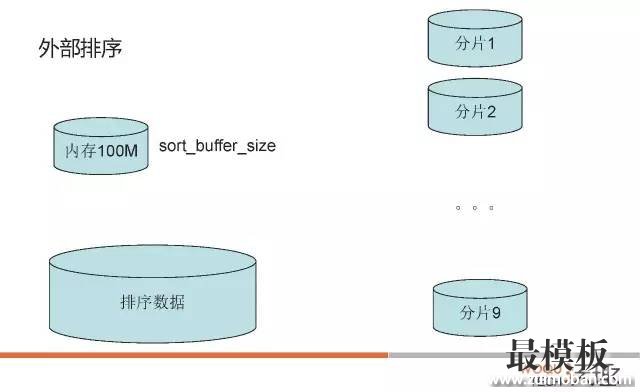
第三种模式主要是解决变长字符数据存储空间浪费的问题,对于实际数据不多,字段定义较长的改进效果会更加明显。 很多文章写到这里可能就差不多了,但是大家忘记关注一个问题了:“如果排序的数据不能完全放在sort buffer内存里面,是怎么通过外部排序完成整个排序过程的呢?” 要解决这个问题,我们首先需要简单查看一下外部排序到底是怎么做的。 五、外部排序5.1 普通外部排序5.1.1 两路外部排序我们先来看一下最简单,最普遍的两路外部排序算法。 假设内存只有100M,但是排序的数据有900M,那么对应的外部排序算法如下:
5.1.2 多路外部排序上述排序算法是一个两路排序算法(先排序,后归并)。但是这种算法有一个问题,假设要排序的数据是50GB而内存只有100MB,那么每次从500个排序好的分片中取200KB(100MB / 501 约等于200KB)就是很多个随机IO。效率非常慢,对应可以这样来改进:
对应的数据量更大的情况可以进行更多次归并。
5.2 MySQL外部排序5.2.1 MySQL外部排序算法那MySQL使用的外部排序是怎么样的列,我们以回表排序模式为例:
这里我们需要注意的是:
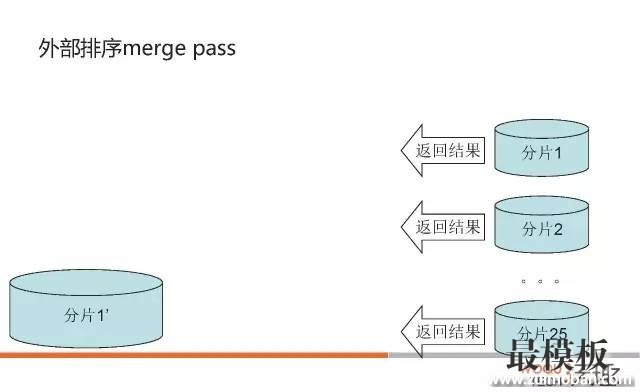
5.2.2 sort_merge_passesMySQL手册中对 Sort_merge_passes 的描述只有一句话 Sort_merge_passes The number of merge passes that the sort algorithm has had to do. If this value is large, you should consider increasing the value of the sort_buffer_size system variable. 这段话并没有把 sort_merge_passes 到底是什么,该值比较大时说明了什么,通过什么方式可以缓解这个问题。 我们把上面MySQL的外部排序算法搞清楚了,这个问题就清楚了。 其实 sort_merge_passes 对应的就是MySQL做归并排序的次数,也就是说,如果 sort_merge_passes 值比较大,说明 sort_buffer 和要排序的数据差距越大,我们可以通过增大 sort_buffer_size 或者让填入 sort_buffer_size 的键值对更小来缓解 sort_merge_passes 归并排序的次数。 对应的,我们可以在源码中看到证据。 上述MySQL外部排序的算法中第5到第7步,是通过sql/filesort.cc文件中 merge_many_buff() 函数来实现,第5步单次归并使用 merge_buffers() 实现,源码摘录如下:
int merge_many_buff(Sort_param *param, Sort_buffer sort_buffer,
Merge_chunk_array chunk_array,
size_t *p_num_chunks, IO_CACHE *t_file)
{
...
for (i=0 ; i < num_chunks - MERGEBUFF * 3 / 2 ; i+= MERGEBUFF)
{
if (merge_buffers(param, // param
from_file, // from_file
to_file, // to_file
sort_buffer, // sort_buffer
last_chunk++, // last_chunk [out]
Merge_chunk_array(&chunk_array[i], MERGEBUFF),
0)) // flag
goto cleanup;
}
if (merge_buffers(param,
from_file,
to_file,
sort_buffer,
last_chunk++,
Merge_chunk_array(&chunk_array[i], num_chunks - i),
0))
break; /* purecov: inspected */
...
}
截取部分 merge_buffers() 的代码如下,
int merge_buffers(Sort_param *param, IO_CACHE *from_file,
IO_CACHE *to_file, Sort_buffer sort_buffer,
Merge_chunk *last_chunk,
Merge_chunk_array chunk_array,
int flag)
{
...
current_thd->inc_status_sort_merge_passes();
...
}
可以看到:每个 merge_buffers() 都会增加 sort_merge_passes ,也就是说每一次对MERGEBUFF (7)个block归并排序都会让 sort_merge_passes 加一, sort_merge_passes 越多表示排序的数据太多,需要多次merge pass。解决的方案无非就是缩减要排序数据的大小或者增加 sort_buffer_size 。 打个小广告,在我们的qmonitor中就有 sort_merge_pass 的性能指标和参数值过大的报警设置。 六、trace结果解释说明白了三种排序模式和外部排序的方法,我们回过头来看一下trace的结果。 6.1 是否存在磁盘外部排序"number_of_tmp_files": 0, number_of_tmp_files 表示有多少个分片,如果 number_of_tmp_files 不等于0,表示一个 sort_buffer_size 大小的内存无法保存所有的键值对,也就是说,MySQL在排序中使用到了磁盘来排序。 6.2 是否存在优先队列优化排序由于我们的这个SQL里面没有对数据进行分页限制,所以 filesort_priority_queue_optimization 并没有启用
"filesort_priority_queue_optimization": {
"usable": false,
"cause": "not applicable (no LIMIT)"
},
而正常情况下,使用了Limit会启用优先队列的优化。优先队列类似于FIFO先进先出队列。 算法稍微有点改变,以回表排序模式为例。 sort_buffer_size 足够大如果Limit限制返回N条数据,并且N条数据比 sort_buffer_size 小,那么MySQL会把sort buffer作为priority queue,在第二步插入priority queue时会按序插入队列;在第三步,队列满了以后,并不会写入外部磁盘文件,而是直接淘汰最尾端的一条数据,直到所有的数据都正常读取完成。 算法如下:
sort_buffer_size 不够大否则,N条数据比 sort_buffer_size 大的情况下,MySQL无法直接利用sort buffer作为priority queue,正常的文件外部排序还是一样的,只是在最后返回结果时,只根据N个row ID将数据返回出来。具体的算法我们就不列举了。 这里MySQL到底是否选择priority queue是在sql/filesort.cc的 check_if_pq_applicable() 函数中确定的,具体的代码细节这里就不展开了。 另外,我们也没有讨论Limit m,n的情况,如果是Limit m,n, 上面对应的“N个row ID”就是“M+N个row ID”了,MySQL的Limit m,n 其实是取m+n行数据,最后把M条数据丢掉。 从上面我们也可以看到 sort_buffer_size 足够大对Limit数据比较小的情况,优化效果是很明显的。 七、MySQL其他相关排序参数7.1 max_sort_length这里需要区别 max_sort_length 和 max_length_for_sort_data 。 max_length_for_sort_data 是为了让MySQL选择 < sort_key, rowid > 还是 < sort_key, additional_fields > 的模式。 而 max_sort_length 是键值对的大小无法确定时(比如用户要查询的数据包含了 SUBSTRING_INDEX(col1, ‘.’,2) )MySQL会对每个键值对分配 max_sort_length 个字节的内存,这样导致内存空间浪费,磁盘外部排序次数过多。 7.2 innodb_disable_sort_file_cacheinnodb_disable_sort_file_cache 设置为ON的话,表示在排序中生成的临时文件不会用到文件系统的缓存,类似于 O_DIRECT 打开文件。 7.3 innodb_sort_buffer_size这个参数其实跟我们这里讨论的SQL排序没有什么关系。innodb_sort_buffer_size 设置的是在创建InnoDB索引时,使用到的sort buffer的大小。 以前写死为1M,现在开放出来,允许用户自定义设置这个参数了。 八、MySQL排序优化总结最后整理一下优化MySQL排序的手段
|
MySQL排序内部原理探秘
时间:2016-10-08 21:20来源:未知 作者:最模板 点击:次
MySQL排序其实是一个老生常谈的问题了,但是我们这次想由浅入深详细说说MySQL排序模式,怎么影响MySQL选择不同的排序模式和怎么优化排序。 同时也希望通过这篇文章解决大家的以下疑



顶一下
(0)
0%
踩一下
(0)
0%
------分隔线----------------------------
- 热点内容
-
- in 和 exists性能研究
从sql编程角度来说,in直观,exists不直观多一个select;in可以用于...
- MySQL删除binlog日志及日志恢复数据
基本上大家装MySQL,都会开启binlog功能,开启这个功能的好处是...
- MySQL性能优化神器Explain使用分析
MySQL 提供了一个 EXPLAIN 命令, 它可以对SELECT语句进行分析, 并输出...
- MySQL修改my.cnf配置不生效的解决方法
本文实例讲述了mysql修改my.cnf配置不生效的解决方法。分享给大...
- MySQL问题之修改my.cnf配置不生效
修改了 my.cnf 配置文件后,却不生效,这是怎么回事? 原因 我们...
- in 和 exists性能研究
- 随机模板
-
-
 ecshop嘀嗒猫零食商城模板
人气:1037
ecshop嘀嗒猫零食商城模板
人气:1037
-
 雅虎代拍代购网站系统
人气:1020
雅虎代拍代购网站系统
人气:1020
-
 Blanco服装饰品英文综合模
人气:1513
Blanco服装饰品英文综合模
人气:1513
-
 ecshop仿蘑菇街2016最新模板
人气:711
ecshop仿蘑菇街2016最新模板
人气:711
-
 综合网店系统|宅品ecshop模
人气:750
综合网店系统|宅品ecshop模
人气:750
-
 空包网刷快递单号自动发
人气:3467
空包网刷快递单号自动发
人气:3467
-