| 关键字描述:教程 简易 采集 我们 内容 网址 如果 作者 V5.3 织梦DedeCms V5.3 采集基础教程。 首先说明一下的是,第一次写这种教程,有不当的地方请大家包涵。 进入正文: 采集过程其实就是copy的过程,只不过,我们copy的是显示结果,而采集主要针对源码进行。 第1步,建立节点 我们以图片中的网址为例,目标页面编码一定要选对,不然采集回来的内容会乱码,如果你采集回来的内容有乱码,首先要考虑的是编码问题,这里我们选utf-8,怎么知道别人的编码是什么呢?看看源码<content="text/html; charset=utf-8" />就会明白了。 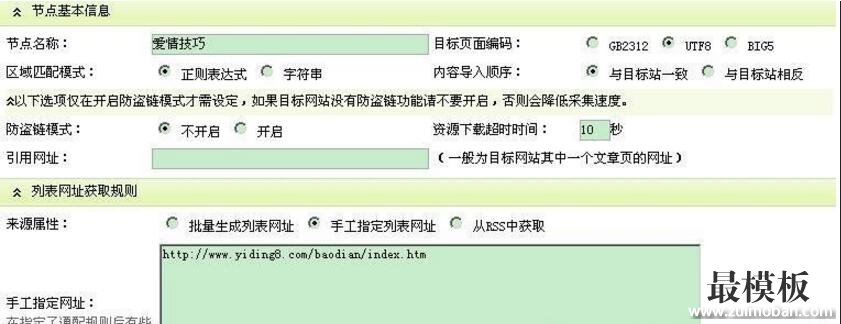 “区域匹配模式”我选择是的正则表达式,因为如果选“字符串”,将有一些广告代码过滤不掉。 第2步:文章网址匹配规则。 生活Tips欢迎您(http://ez4life.cn) 这个就要看采集网站的源代码(图2)了,找到一个包含所有要采集内容网址的代码(要唯一,建议多使用Ctrl F),这样我们就确定了要采集区域的网址,不放心就测试一下。  图2 最后结果如图3  图3 第3步:在前面2步的基础上我们已经找到了需要采集的网址,下面来看具体的采集内容。 在内容配置选项中,如果你比较懒,可以象我一样不要选那么多的选项,只选择你感兴趣的部分,如文章标题,作者及来源等,在dede cmsV5.3中已经把dede V5.1的规则进行了改造,易于初学者使用了,其基本形式是标签和内容放在一块的,V5.1要分开始标签和结束标签,其实原理都是一样的。 这里讲讲自定义作者的问题。V5.3以前的版本采集时可以用@me="作者“的形式自定义作者,而v5.3只能用替换的方法实现了,当然也有不便之处,这样我们就确定了基本的东西了。 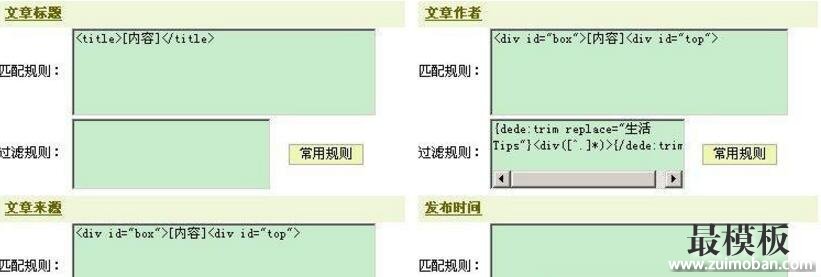 第4步:便是我们要的内容核心了,这里会用到比较多的过滤规则,幸好dede V5.3给我们准备了一些常用的,不过,如果你想采集比较复杂的网页那还得学会一些常用的正则表达式了。这样我们就基本学会了dedecms V5.3的采集,是不是有点简单? 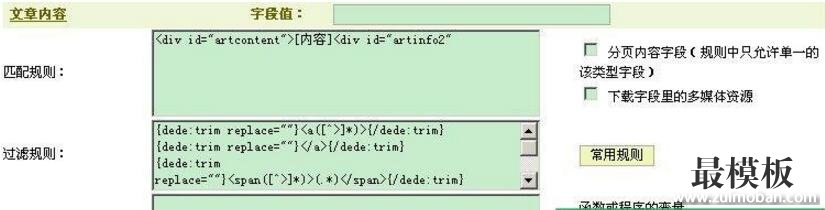 第5步:导出内容,这个我就不多讲了。 (责任编辑:最模板) |
织梦DEDECMS V5.3采集简易教程
时间:2017-01-28 11:52来源:未知 作者:最模板编辑 点击:次
关键字描述:教程 简易 采集 我们 内容 网址 如果 作者 V5.3 织梦DedeCms V5.3 采集基础教程。 首先说明一下的是,第一次写这种教程,有不当的地方请大家包涵。 进入正文: 采集过程其实
顶一下
(0)
0%
踩一下
(0)
0%
------分隔线----------------------------
- 热点内容
-
- 发一个自定义标签源码 读取远程文
织梦dedecms主要功能是读取远程页面的代码放到需要调用的地方。...
- 如何解决php.ini register_globals must i
最近在帮助朋友解决一些问题时发现,部分使用织梦DEDECMS的朋友...
- DEDECMS文章地址优化方法:目录式结构
织梦DEDECMS文章地址优化方法:目录式结构。 关键字描述:目录...
- 怎样删除DedeCMS5.7后台登陆界面广告
怎样删除织梦DedeCMS5.7后台登陆界面广告位 。 织梦DedeV5.7发布也...
- 织梦网站文章和栏目的自定义字段
在制作织梦dedecms模板的过程中经常会用到一些默认dedecms没有的...
- 发一个自定义标签源码 读取远程文
- 随机模板
-
-
 亚洲产品外贸ecshop模板
人气:825
亚洲产品外贸ecshop模板
人气:825
-
 ecshop精仿okbuy好乐买2012免
人气:3624
ecshop精仿okbuy好乐买2012免
人气:3624
-
 ecshop仿米奇网化妆品2014网
人气:549
ecshop仿米奇网化妆品2014网
人气:549
-
 Ecmall仿天猫2014多店铺商城
人气:2515
Ecmall仿天猫2014多店铺商城
人气:2515
-
 名鞋库shopex模板|鞋子商城
人气:718
名鞋库shopex模板|鞋子商城
人气:718
-
 ecshop蔬菜水果模板|蔬菜水
人气:2128
ecshop蔬菜水果模板|蔬菜水
人气:2128
-